Legacy single machine migration guide
Migrate from legacy single machine to a high availability cluster.
Prerequisites
To get started with your migration from legacy single machine to a high availability cluster, you’ll need the following prepared in advance:
- Kubernetes cluster running at least version
1.25and at most version1.35 - Docker registry
- Single machine BugSnag On-premise instance with the latest version installed
- Ruby 2.7 or higher on the single machine BugSnag On-premise instance
Migration Overview
The migration process has the following steps:
Migrating the configuration – Converts the configuration on the single machine instance to the Clustered version.
Configuring the instances to run in migration mode – Configures single machine and Clustered instances to connect to each other to migrate the data.
Migrating the databases – Moves data from the single machine instance to the Clustered instance. Any new events processed in the single machine instance are migrated over. The Clustered instance will not process any events sent to it.
Configuring the instances to disable migration mode – Configures single machine and Clustered instances to disable migration mode. Once done the instances are not connected to each other and will process events separately. After this point you cannot go back to migration mode.
Running the Post-Migration Script – Executes necessary database upgrades and reconfigurations on the clustered instance post-migration.
It is highly recommended to run Clustered On-premise in non-migration mode first before attempting a migration to ensure that the cluster is setup correctly. You can then clear the data prior to a migration by running kubectl delete namespace bugsnag.
When configuring the Clustered instance make sure the cluster is using appropriately sized nodes and the storage sizes for the databases are set correctly as these cannot be changed very easily after the migration is complete. Please contact us for recommendations according to your usage.
Once the migration has been completed and both instances are running in non-migration mode, you can safely change the DNS to route traffic to the new instance or reconfiguring the notify / session end-points in the application.
Running the migration
The migration can take some time and is dependent on the number of events you have, however you can continue to use your current single machine instance whilst the data is migrating. We estimate that it takes around 1 hour to migrate 8 million events of data. There will be some downtime after the data has been migrated and Clustered BugSnag On-premise starts, this may take around 10-15 mins.
Migrating the configuration
Download migrate-settings.rb on the single machine instance. Run the following command: ruby migrate-settings.rb. This will generate a config required for the migration: config.yaml.
Copy config.yaml to where you will be starting the migration.
Install Replicated KOTS admin console
Follow the standard or airgapped installation guide to install Replicated KOTS. When you reach the step to install the admin console, supply your current license and migration config. For example:
kubectl kots install bugsnag-clustered-kots \
--name Bugsnag \
--namespace bugsnag \
--license-file ./license.yaml \
--config-values ./config.yaml
Migrate databases
On the clustered instance, in the configuration tool available at http://localhost:8800:
In the config section under Migration: Enable migration mode by ticking the checkbox:
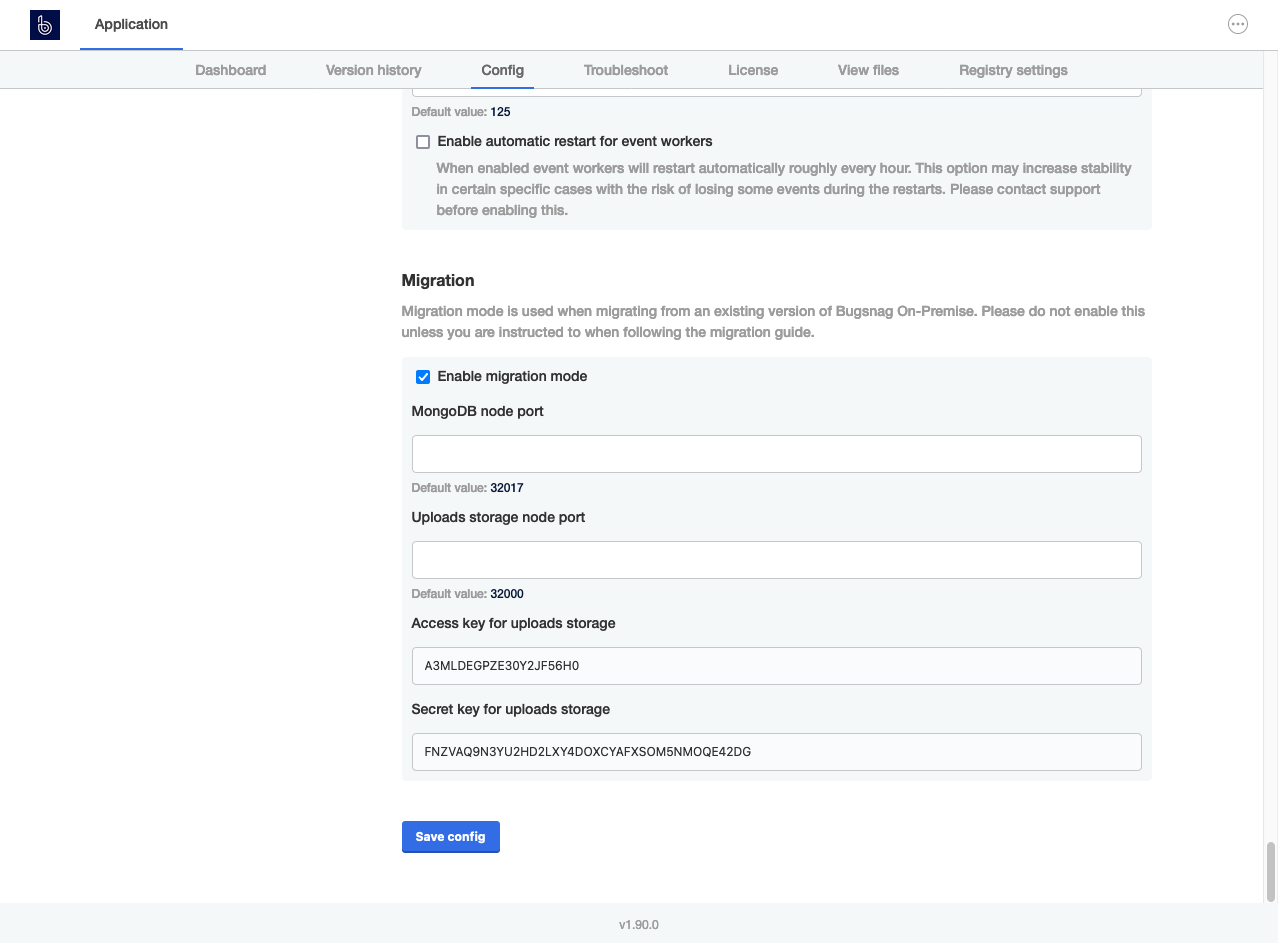
(Optional) Configure the “MongoDB node port” and “Uploads storage node port” settings under the Migration section.
Configure BugSnag to the settings you want to be using after the migration has completed in particular make the sure the following configuration is set correctly:
- Enable high availability features under the Kubernetes section if you are going to be running BugSnag in high availability mode after migration has completed:

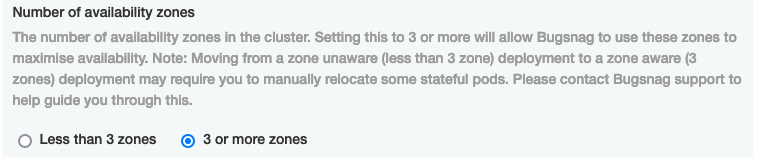
- Ensure the number of availability zones is set correctly under the Kubernetes section:
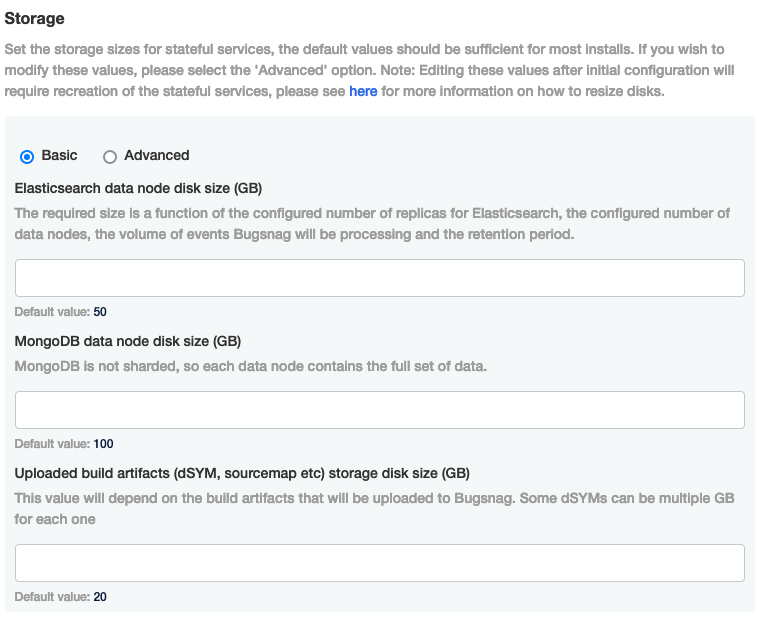
- Ensure that the storage sizes for the stateful services under Storage are set correctly as editing these values after initial configuration will require recreation of the stateful services:
- Enable high availability features under the Kubernetes section if you are going to be running BugSnag in high availability mode after migration has completed:
Click “Save config” to deploy BugSnag. Make a note of the values in the migration config section which will be required as configuration on your single machine Bugsnag instance.
On the single machine instance:
Configure via Replicated settings to enable migration mode:
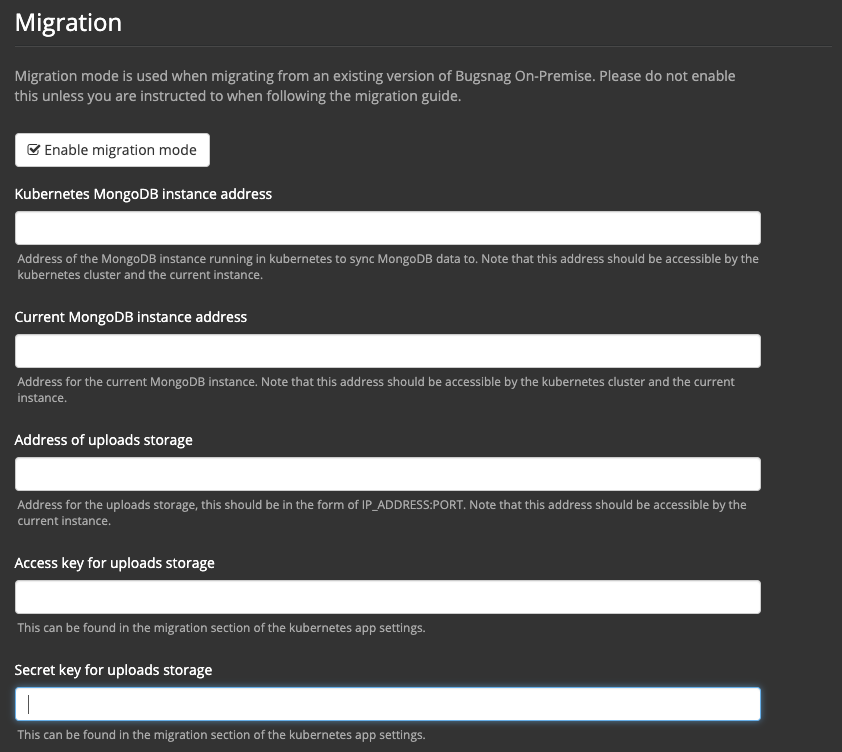
Setting Value Kubernetes MongoDB instance address Address of the MongoDB instance running on Kubernetes: Kubernetes Node IP:MongoDB node port
This address should be accessible from the single machine BugSnag instance.Current MongoDB instance address Address of the MongoDB instance running on the single machine BugSnag instance: single machine instance IP:57017
This address should be accessible from the Kubernetes cluster.Address of uploads storage Address of the uploads storage instance running on Kubernetes: Kubernetes Node IP:Uploads storage node portAccess key for uploads storage Use the value from the earlier output. Secret key for uploads storage Use the value from the earlier output. Save and restart BugSnag when prompted, the migration will start once BugSnag has restarted. You can check the progress of the migration using the instructions below:
Monitoring uploads migration progress
You can check the progress of the uploads migration by running the following on the single machine BugSnag instance:
docker logs bugsnag_migrate-uploads
Once this states “Migration of uploads completed.”, this migration is complete.
Monitoring MongoDB migration progress
You can check the progress of the MongoDB migration by checking the status of the replica set:
kubectl -n bugsnag exec -it mongo-0 -- mongo-local --eval "rs.status()"
If the MongoDB instance in Kubernetes is in STARTUP2 mode you can check the progress of the collection copying using:
kubectl -n bugsnag logs -f mongo-0 | grep "repl writer worker"
Once the instance is in SECONDARY mode you can use the following to check the replication lag:
kubectl -n bugsnag exec -it mongo-0 -- mongo-local --eval "rs.printSlaveReplicationInfo()"
Once this states that the MongoDB instance is 0 secs behind master, this migration is complete.
Migrate redis
Once MongoDB has finished migrating run migrate-redis.sh on the single machine BugSnag instance and select “Backup redis data” option to begin backing up the redis data from the instance.
Once that has completed you can use the “Restore redis data to kubernetes” option to begin the restore.
If you do not have access to the Kubernetes cluster from that instance you should copy the output archive to an instance which does along with the script and run migrate-redis.sh using the restore option and specifying the archive location to begin migrating the redis data to the Clustered instance.
Configuring the instances to disable migration mode
Note that once migration mode has been disabled on both instances any new events sent to the single machine instance will not be migrated.
There will be a period of downtime until the Clustered installation is fully running and the error traffic has been routed over to the new instance.
Migration mode cannot be re-enabled once it has been disabled. You will have to start the migration from scratch.
Once all the migrations are complete, to disable migration mode and run the two instances separately:
On the single machine instance configure the single machine BugSnag instance via Replicated settings to disable migration mode and restart:
Run the following to allow access to the Replicated KOTS admin console for the clustered installation:
kubectl kots admin-console --namespace bugsnagDisable migration mode and deploy the config change.

Post-migration actions
Elasticsearch reindex
Once BugSnag is running, Elasticsearch will require a reindex, which you can monitor using “Events in Elasticsearch/Mongo” graph under the “Support” dashboard on Grafana. There will be a period where historical events will not be available in the dashboard until the reindex has completed, any new events will show up on the dashboard immediately. We estimate that it takes around 1 hour to reindex 1 million events of data.
Reconfigure Grafana notifications
Grafana notifications are not migrated as part of the legacy single machine to high availability cluster migration. You will need to reconfigure any legacy single machine Grafana notifications in your high availability cluster after the migration has completed.
To configure Grafana notifications in your high availability cluster please refer to our monitoring your instance documentation.